






데이터분석과 예측모델 연구
데이터분석과 예측모델 연구
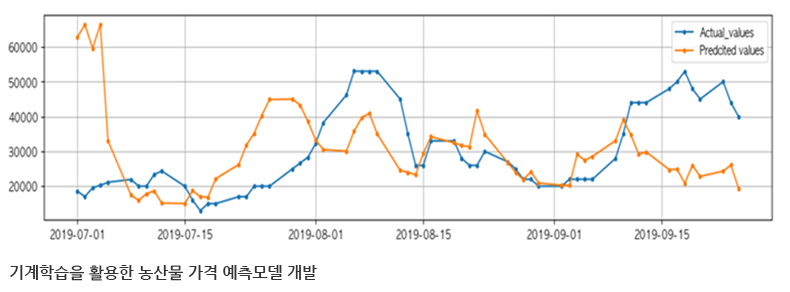
기계학습을 활용한 의료데이터 분석과 질병을 예측하는 모델을 연구하고 있습니다. 이를 기반으로 의료분야를 포함한 다양한 분야의 문제해결을 위한 예측모델 개발과 이를 적용하기 위한 연구를 함께 진행하고 있습니다.
주요 연구 내용
- 데이터를 활용한 기계학습 기반 질환 예측모델 개발
- 데이터 기반 기계학습 알고리즘 개발
- 산업계, 의료계의 문제 해결

컨텐츠담당자
현윤경 042-717-5710710
최종수정일 2022-10-06
