NIMS Research
신소재 예측과 개발의 길, 수학이 확! 앞당긴다
‘열전 소재 연구를 통하여 기계학습 기반 물성 예측모델 결과가 주요 국제 학술지에 게재’
새로운 소재 개발은 새로운 산업으로의 시작으로 이어질 수 있다. 따라서 세계 각국은 신소재 개발을 위한 경쟁으로 치열하다. 국가수리과학연구소 또한 수리과학을 기반으로 대한민국 소재산업의 경쟁력을 강화하기 위한 연구 프로젝트를 과학기술정통부의 ‘나노·소재원천기술개발사업’을 통하여 다년간 추진 중이다. 해당 사업의 과제인 ‘신소재 예측과 개발을 위한 수리과학 기반 데이터 분석기술 연구개발’을 통하여 ‘기계학습 기반 페로브스카이트 물성예측모델 결과가 주요 국제 학술지에 게재’되는 성과를 거뒀다.

빅데이터를 기반으로 한 소재 혁명에 나서다
국가수리과학연구소 현윤경 팀장은 ‘신소재 예측과 개발을 위한 수리과학 기반 데이터 분석기술 연구개발’ 과제를 수행하며 두 가지 연구방향을 계획했다. 하나는 신소재를 빠르고 효율적으로 예측·설계할 수 있는 기계학습에 기반을 둔 인공지능형 방법론을 찾아 개발의 성공모델을 보여주는 것. 또 하나는 그 방법이 성공적으로 개발된다면 다른 응용분야에도 적용할 수 있도록 플랫폼의 기반을 구축하는 것이다. 현윤경 팀장의 과제 성과에 대해 이야기하기에 앞서, 이러한 연구방향을 계획하게 된 배경을 먼저 짚어보고자 한다.
4차 산업혁명 시대가 도래하면서 소재개발 연구분야에 새로운 바람이 불었다. 데이터 분석을 기반으로 한 연구방식인 ‘데이터 드리븐 리서치(Data-Driven Research)’가 새로운 연구개발의 패러다임으로 인식되기 시작한 것이다. 따라서 미국을 비롯한 선진국은 수 년 전부터 계산과학(주로 컴퓨터 계산을 이용해 수학적 모델을 해석하는 방법으로 연구 대상을 이해하는 학문) 기반의 빅데이터를 구축·공개하는 움직임을 보이고 있다. 그 대표적인 예가 미국에서 시작된 ‘소재 게놈 특별계획(MGI, Material Genome Initiatives)’이다. 이 프로젝트는 소재분야 연구개발 활성화를 통해 신소재 개발부터 활용까지의 기간과 비용을 대폭 줄이기 위한 목표를 갖고 시작됐다.
소재 게놈 특별계획은 기존 연구개발 패러다임의 변화, 소재 데이터 구축, 관련 인력 양성 등 다양한 목표를 추구한다. 특히 소재 데이터 구축의 경우, 각종 실험, 계산, 이론 등에 대한 데이터를 구축하고 이를 연구자들이 쉽게 이용할 수 있는 환경을 제공하고자 했다. 그 일환으로 만들어진 대표적인 소재 빅데이터 웹사이트가 바로 Materials Project(https://www.materialsproject.org) 이다. 이곳에는 무기화합물, 분자, 다공성 물질 등 다양한 소재의 구조와 성질 약 60여만 개가 게재되어 있다.
하지만 이렇게 공개되어 있는 데이터가 완벽하진 않다. 데이터를 가져와 기계학습 등 데이터 분석을 하기 위해서는 활용 용도에 맞춰 필요한 물성과 특성을 계산하는 후처리가공(post processing)이 필요하다. 현윤경 팀장은 공개된 소재 빅데이터를 활용해 고효율의 태양열 신소재 후보물질을 예측·개발하는 한편, 한국화학연구원과 공동연구로 수집된 열전소재 실험 빅데이터에서 후처리가공하여 고효율 열전소재 후보물질 예측에 필요한 데이터를 모델링하는 연구도 수행 중이다. 또한 이 데이터 모델링을 통하여 기계학습 기반 인공지능형 예측모델 연구를 수행 중이다.
기존 열전소재가 가진 한계를 넘어설 후보물질을 찾아라
최근 미국 하버포드 컬리지와 퍼듀 대학교의 연구진에 의해 기계학습으로 실패한 실험 데이터를 분석해 새로운 물질을 합성하는 방법이 제시되었다. 이 연구는 그간 버려졌던 실험 데이터를 재활용해 새로운 정보를 만들어냈다는 점에서 상당히 고무적이며, 앞으로 소재 빅데이터를 구축하는 데 핵심적인 방향을 제시한다. 현윤경 팀장은 공동연구기관과 함께 해당 과제에서 실패한 실험 데이터까지 활용·수집할 수 있고, 조합화학(단일 공정에서 다양하고 매우 많은 수(수백 개~수백만 개)의 화합물을 만들 수 있는 화학 합성 방법 중의 하나)으로 합성 및 평가가 가능해 실험 데이터를 자동적으로 확보하기 수월하며, 향후 주목받은 스마트소재 분야를 먼저 공략하기로 했다. 그것이 바로 열전소재이다.

열전소재는 버려지는 에너지를 수집해 전기로 바꿔 쓰는 기술인 차세대 에너지 하베스팅(Energy Harvesting)의 핵심 소재다. 자동차, 제철, 우주, 항공 분야 산업에 널리 사용될 수 있는 잠재력을 가지고 있어 최근 새롭게 각광받고 있다. 우리 삶 가까이에서 쉽게 찾아볼 수 있는 활용처를 꼽자면, 내연기관 자동차의 폐열(배기관열)을 전기로 바꿀 수 있다. 예를 들어, 이 기술을 자동차에 활용하면 하이브리드 자동차의 전기효율을 높일 수 있다.
기존 열전소재가 가진 특성은 고온에서 열전효율이 나와 적용할 수 있는 조건이 제한적이라는 것이다. 열전소재가 한 단계 더 업그레이드되기 위해서는 좀 더 낮은 온도에서도 열전효율이 높은 신소재 후보물질을 찾아야 한다. 현윤경 팀장은 기계학습을 활용해 열전소재의 물성을 예측할 수 있는 모델을 개발하고 있다. 또한 이 과정에서 연구된 물성예측 모델을 태양열 소재의 주요 물성의 합성 가능성을 나타내는 표준생성열(Heat of formation)과 전기적 특성을 나타내는 밴드갭(Band gap)을 예측했다.
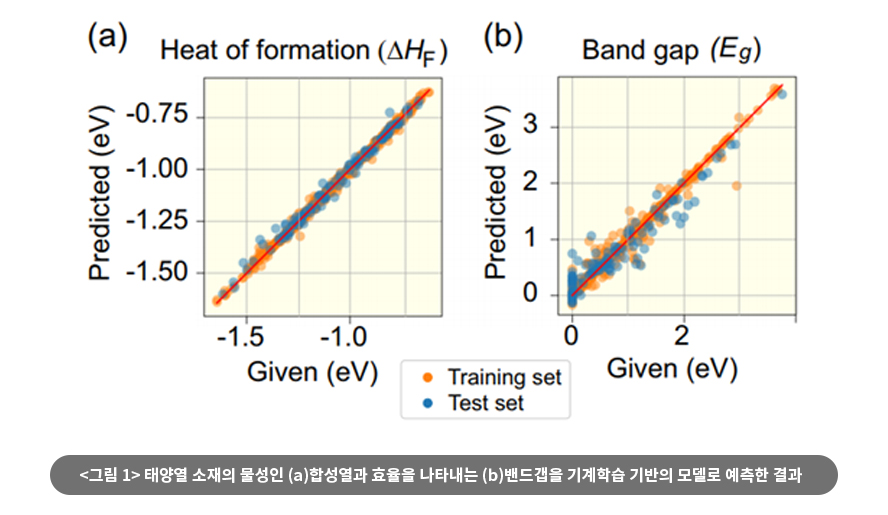
해당 사업에서는 앞으로 열전소재의 조성, 도핑원소, 도핑레벨, 합성조건 등 다양한 조합에 대한 제일원리 계산과 측정 실험을 통해 소재 빅데이터를 축척하고자 한다. 또한 소재물성 예측에 최적화 된 빅데이터 해석 기술과 기계학습 기반 인공지능형 기술을 개발해, 산업에 직접적으로 응용할 수 있는 예측모델 개발하고 후보물질을 도출하는 것이 궁극적인 목표다.
사람이 하기 힘든 소재물성 탐색, AI가 대신할 그날
앞서 이야기 했듯, 미국 등 선진국에서 무료로 공개하는 소재 빅데이터는 대부분 계산과학 기반의 결과를 제공한다. 하지만 해당 데이터를 기계학습에 활용하기 위해서는 데이터 수집 후 후처리가공 단계가 필수적이다. 이에 국가수리과학연구소와 한국화학연구원이 공동연구를 추진해 공개되어 있는 소재 빅데이터로부터 데이터를 수집해 후처리가공한 데이터까지 구축했다.

두 연구기관의 공동연구는 여기에서 그치지 않았다. 공개된 태양열 소재 데이터인 CMR(Computational Materials Repository, https://cmr.fysik.dtu.dk/)에서 제공하는 더블 페로브스카이트 산화물(Double perovskite oxides) 데이터로 밴드갭 예측을 하고자 다양한 기계학습 알고리즘을 활용해 비교해보았다.
이중 페로브스카이트 산화물의 밴드갭 예측에 기계학습 활용의 가능성을 보여준 기존의 논문 Pilania et al. (2016)에서는 비교적 간단한 커널 리지 회귀분석(Kernel Ridge Regression) 방법이 사용되었다. 국가수리과학연구소와 한국화학연구원의 공동연구에서는 결정 트리(Decision Tree, 알고리듬을 시각적으로 표현하여 의사를 결정하거나 시간 복잡도를 증명하는 데 사용하는 트리) 기반의 다양한 머신러닝 방법이 적용됐다. 그 결과 기존 방법보다 두 연구기관이 공동연구한 기계학습 방법론이 더 나은 결과를 보여준다는 결론을 얻었다. 더불어 소재물성 예측에 기계학습을 활용하기 위해서는 다양한 방법론에 대한 검증과 새로운 알고리즘 개발, 다양한 속성공학(Feature engineering)이 필요하다는 것을 알 수 있었다.
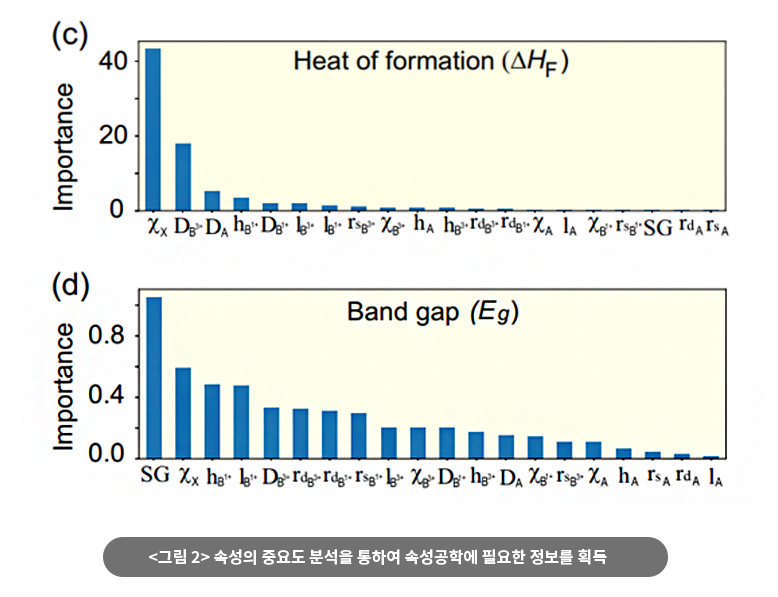
신소재 개발 과정 중 ‘소재 디자인’은 보통 7년 정도의 시간이 걸린다. 국가수리과학연구소는 ‘후보물질 도출’ 단계에서 소요되는 시간을 획기적으로 단축하는 연구를 수행함으로써, 3~4년 이상 단축하는 것을 목표로 하고 있으며, 태양열 소재에서 결과를 얻음으로써 그 가능성을 확인하였다.
인류 문명의 성장은 신소재의 발견, 개발과 함께 했다고 해도 과언이 아니다. 신소재가 탄생하는 순간마다 우리의 삶이 변화하고 성장했기 때문이다. 그런 측면에서 ‘신소재 예측과 개발을 위한 수리과학 기반 데이터 분석기술 연구개발’ 과제는 의미가 남다르다. 신소재 예측과 개발 과정에 있어 수리과학의 힘을 보여줄 뿐만 아니라, 우리의 삶을 바꿀 신소재의 탄생을 앞당길 수 있기 때문이다.